
Ever see a “low risk” change cause major issues? “We’ve done it before and never had any problems” doesn’t cut it in the aftermath of a business-impacting incident caused by a “low risk change”.
Let’s be clear – all IT changes have risk. Some more than others. Effective Change Management ensures change risks are analyzed and appropriately managed. Risk Analysis then, as it relates to Change Management, is risk to the business. Not risk of technical failures, or IT related issues – but the risk the proposed change presents to the organization over all.

The kind of risks in view here are things like:
- Anticipated features not available (or not performing correctly)
- New features not available, or not working right
- Users unsuccessful in using the service to achieve business objective(s)
- Other parts of the service (or other services) not working correctly
- Service not available for use
- Slow performance
All of which come down to a variation of:
Will I be able to do business after the change is made?
With that said, here’s a practical approach to Risk Analysis in managing changes.
Identifying the threats
To start with, for any given change, list as many threats as you can. As your risk analysis practice matures, you’ll hone in on the key threats, but for getting started, its enough to brainstorm threats that have some possibility of actually happening.
One of the defining differences between simply assigning a risk level to a change (i.e. “low risk change”) and doing proper risk analysis is that the latter requires identification of specific threats. Threats, as in ‘what could possibly go wrong’.
Let’s say we’re going to perform a major operating system upgrade to a server. What bad things could happen associated with the upgrade?
- Server doesn’t restart after upgrade
- Applications don’t run correctly
- Application(s) run unusably slow
- Application(s) run, but cannot access the database
Obviously, you can go overboard identifying too many threats – some of which are highly unlikely to happen. This is not only unhelpful, but serves to undermine the actual goal – managing change risks.
Analyzing the Risk – How likely to happen?
Next, for each identified threat, we need to assess the probability of the threat actually happening, and if it does, to what degree will it impact the business?
Let’s take ‘server doesn’t start after upgrade’.
To determine how probable it is to happen, consider things like:
- For this platform, have we seen this happen before?
- Have we recently made this upgrade (OS version & server hardware) on other servers?
- How old is the hardware (or virtualization platform)?
- How complex is the server configuration?(single/multiple application, third party middleware or databases hosted on the same platform)
- What’s the word on the street (social media, tech forums)?
Depending on your needs, probability can be quantified in many ways, but I’m a fan of simplicity – Low, Medium, High.
In our server OS upgrade example, then, lets say that our analysis shows the server team successfully performed this upgrade multiple times in the last month with no noticeable issues. Each time they take snapshots (point-in-time backup) just prior to applying the upgrade. Six months ago testing of the Disaster Recovery plan included successful restoration from snapshots.
This is really sounding like a Low probability risk.
Risk Analysis – how bad is ”bad”?
Next, we need to assess business impact if said risk happens.
Here, we consider things like:
- Do we understand the criticality of the desired business outcome(s)?
- Stakeholder commitments
- Financial impact
- Has the business been consulted on the timing and risk of proposed change?
- Business cycles (pasterns of business activity)
- Can the service be fully restored during agreed change window?
- Is there redundancy that keeps service up while implementing the change?
- Do we have spare hardware on hand?
- Is there a tested and documented recovery/rollback plan in place?
And, in the end, as above, we wind up giving Low, Medium, High rating of the impact if the specific threat were to occur.
Back to our upgrade – in this case, let’s say that the server is a single hardware (non-virtual) server that is reaching end-of-life. Further, the business uses the application daily – including early morning and late at night by accounting teams to execute complex financial transactions for global customers.
Sure, you can say that’s a bad design (aging, single server hosting mission-critical applications), but it’s more common in the “real world” than you would care to believe
Clearly, that makes the impact of the server not restarting High.
Combined risk
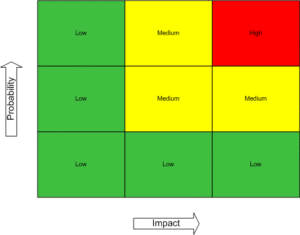
A simple risk matrix is helpful. For each threat, plot where the the probability and impact intersect.
When mapped on a simple grid, the combined risk score is High. (While the probability is low, the impact is high, putting the combined score in the upper right (high risk)). This is a high risk change, even though there’s no technical concern with the upgrade itself.
It’s worth noting that it’s a good practice to pre identify high risk infrastructure components (network segments, routers, servers, applications, etc.) For critical business services, it’s not uncommon to label all supporting components as ‘high risk’. In other words, any change to that component are always treated as a High risk change.
Likewise, certain change types may be labeled as High risk based on organizational culture, or previous experience. (i.e. remember when that change brought down manufacturing for 3 days!?) Regardless of current state, organizations may choose to treat all future or similar type to be High risk as well.
The bigger point here is that it’s always risk to the business that is in view, not technical or IT-focused risk. Further, risk management is a business decision, and IT operational practices must reflect the business’ appetite for risk (and the appropriate management thereof.)
Risk Mitigation
While practices vary greatly in organizations, a good practice is to focus on High risk threats, and develop risk mitigation strategies for each. These strategies must be realistic, workable measures that provide a certain level of confidence in the ability to continue to support the business in the event the risk scenario actually occurs.
Don’t follow the bad practice of using vague generalities (“fix whatever comes up”), untested plans (“we’d go to the local electronics store and buy a big ole PC and use it as a server”), or plans that sound good, but in reality are nothing more than a good thought (but not actually in place or practical).
Depending on the needs of the organization – you may also consider putting moderate plans in place for Medium risk scenarios. In this way, you’ve at least thought though possible measures that could be taken. It stands to reason that the higher the risk, the more diligence that should be applied to the mitigation plans.
Here again, risk mitigation plans must align with the business, recognizing that risk mitigation planning and execution have real costs and are only justified by meeting the needs of the business.
Where to from here?
Of course, the goal is to reduce negative impact to the business.
Identifying specific threats and doing the analysis opens the door to continual improvement in the form of a feedback loop. When changes go awry, a Post Implementation Review (article coming soon!) will determine if the failure was identified as a threat, and if it was properly rated for probability and impact. Any mitigation strategies can be evaluated for effectiveness. What we learn in the process informs future risk analysis and improves the organization’s Change Management capability.
Need more help with change risk analysis and mitigation? Check out my recent HDI webinar on change related risk.

